Playlist Analyzer for Spotify
Created by Matt Levin
Is it possible for a computer to automatically identify your taste in music and generate playlists of new music that you would enjoy based on your Top 100 most played songs? Can multiple users’ Top 100 playlists be used to instantly create a collaborative playlist for a group study session, or to visualize the differences in their music tastes?
Inspired by Spotify’s 2017 Wrapped feature, I set out to determine what insights could be gathered from users’ Top 100 playlists and how to apply this data in a meaningful way. After collecting Top 100 playlists from 12 different Spotify users, I began working on various functions using the Spotify Web API to see what could be done with the data.
This project is built around the Spotify Python Wrapper, Spotipy, using various tools such as scikit-learn and pandas. Note: Although much of this project is designed with Top 100 playlists in mind, it is still generally applicable to any playlists used as input.
Summary
This project contains various functions to draw insights and create customized playlists based on Spotify users’ Top 100 playlists. In addition to playlists tailored to a single user’s tastes, playlists can be generated using multiple users’ Top 100 lists and be catered for specific situations, such as dancing or studying. This framework is easily adaptable to be used for other scenarios, and leads to instantly generated collaborative playlists that a whole group can enjoy. I have been able to share these customized playlists with the users who sent me their Top 100 lists, and received a lot of positive feedback on both the individual and group playlists. Other features besides playlist generation are also included in the project, including finding the top artists in a playlist and clustering the data based on various audio features. Although these are the major functions so far, there are a plethora of fun and useful potential features for end-users waiting to be made using this sort of data and analysis.
Features
This project consists of several features listed below, with more details about each in the following subsections.
- Classify which playlist a song is most likely to be in based on its audio features.
- Predict which songs a user would enjoy, creating a Spotify playlist musically similar to their Top 100 playlist.
- Generate a playlist of the most danceable songs from a group of source playlists.
- Make a playlist of the tracks best suited for quiet studying from multiple input playlists.
- Find and display the artists with the most tracks in a playlist.
- Cluster the tracks from multiple playlists based on any subset of audio features, and visualize the resulting clusters.
Note: See the Usage and Sample Output sections for instructions on how to run each feature and example results.
Playlist Classification and Prediction
For each input playlist, metadata and audio features (obtained from the Spotify API) of each track are written into a CSV file (spreadsheet). The data from all the input playlists is then used to train a model to classify which source playlist a given track is from based on the audio features of the track. Once trained, the model can then be used to generate a playlist of tracks that it predicts would most likely be from a given playlist. In other words, it picks tracks that the user would enjoy since they are musically similar to the songs in their Top 100 list, which were used in training the model. For each track, the trained model gives a probability that it is from a given playlist. So by choosing the tracks with the highest probability of being from the selected source playlist, it generates a playlist that mirrors the audio profile of the original playlist.
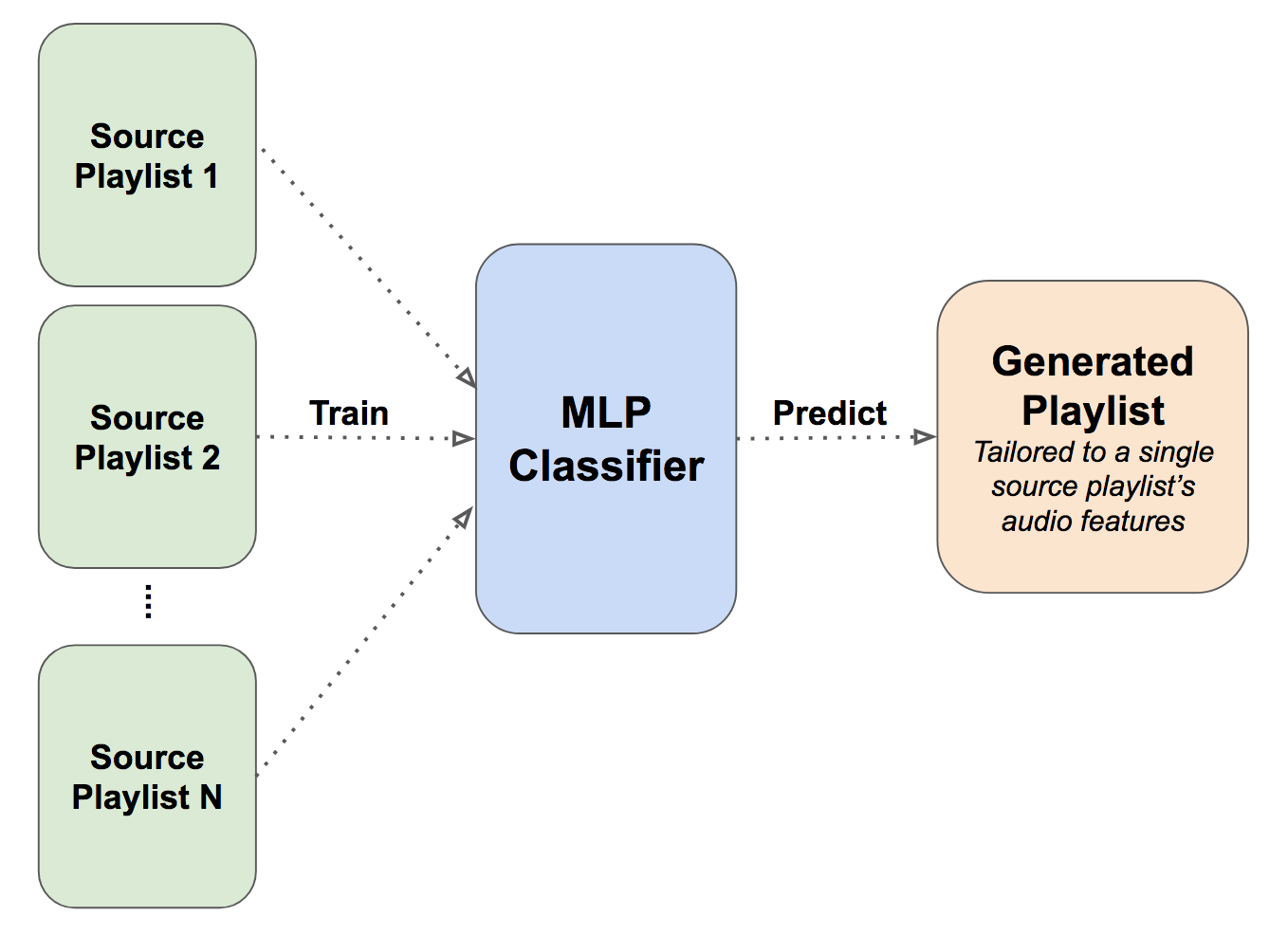 This figure shows how the model is trained to identify which source playlist a track is from, and then generates a playlist tailored to a single playlist’s audio features once it has been trained.
This figure shows how the model is trained to identify which source playlist a track is from, and then generates a playlist tailored to a single playlist’s audio features once it has been trained.
Either a Multilayer Perceptron (MLP) classifier (sklearn.neural_network.MLPClassifier) or a Gaussian Naive Bayes classifier (sklearn.naive_bayes.GaussianNB) can be trained as the model for classification. However, I have found that the MLP classifier performs better on this dataset, so it is the model used in playlist generation. Any combination of audio features can be used in the training and prediction, however by default all available features are used.
Group Playlist Generators
Another neat feature is the generation of custom group playlists for either dancing or studying, by selecting a few tracks from each input playlist. For example, if 4 friends are studying together and want to play music they will all enjoy and be able to study to, this tool would automatically choose the best songs for studying from each of their Top 100 playlists. This way, all the users in the group would enjoy the playlist since it is sourced from their own playlists, and it is optimized for studying by utilizing Spotify’s audio features for each track. This tool could be a great feature from a social perspective, since it tailors a playlist not just to one user, but to a group of users.
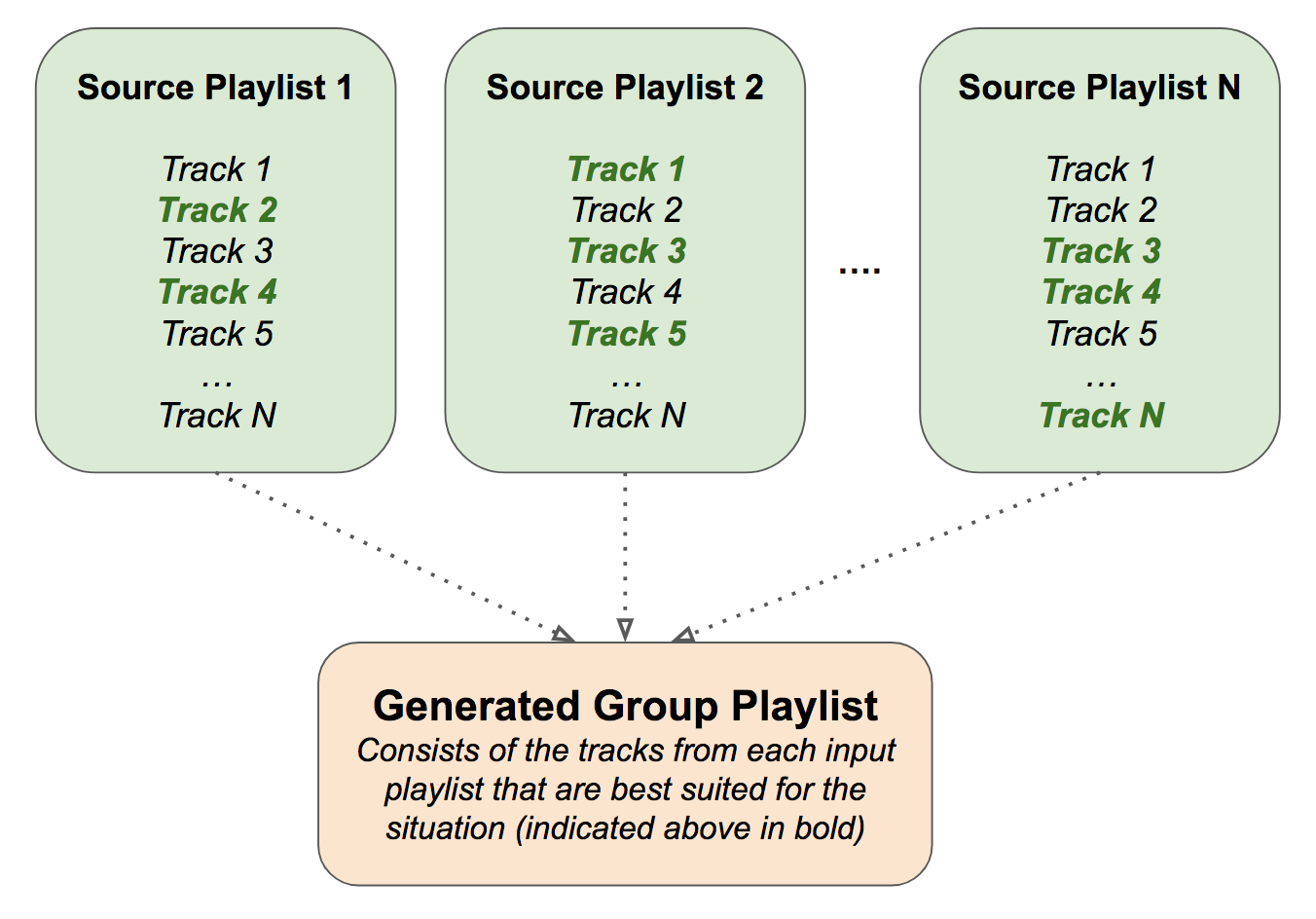 This diagram shows how the tracks that are best suited to the given situation are selected from each source playlist, and then put into a newly generated Spotify playlist that reflects all the users’ tastes.
This diagram shows how the tracks that are best suited to the given situation are selected from each source playlist, and then put into a newly generated Spotify playlist that reflects all the users’ tastes.
The dance party function uses a combination of the danceability and energy audio features to choose the tracks, while study buddies uses instrumentalness, acousticness, energy, and speechiness. The choice to use these combinations of audio features intuitively make sense, at least in my opinion, for creating a playlist conducive to dancing or studying. By simply adjusting which audio features are used to make the selections, this framework is easily adaptable to other situations well beyond dancing and studying, such as working out or road trips. Additionally, the source playlists don’t need to be Top 100 playlists, so users could input their own study playlists to generate a new playlist of the songs deemed best for studying from each of the input playlists.
Top Artists in a Playlist
This feature extracts the artists who show up most often in a given playlist, and displays their names and how many of their tracks are in the playlist. It takes into account the fact that songs can have more than one artist, and also shows the total number of artists who are present in the playlist. Although less technically advanced than the previous two features, this feature was requested by some of the users who sent me their Top 100 lists, and I was also curious to find out about my own playlist.
Cluster Visualization
Clustering can be performed on the data using any combination of audio features. After the clusters are found, several plots are created and shown to the user. To reaffirm the belief that different users’ playlists have very different audio trends, the cluster distributions for each playlist is shown as a bar chart. After that initial plot is displayed, a scatter plot is shown for each pair of audio features. See the Sample Output section below for examples of these plots. The features used in plotting can also be customized, and a feature can be specified for the x-axis or y-axis so that only the plots with that feature are shown (i.e. if you only wanted to see plots with energy on the y-axis). Both Gaussian Mixture Model and Spectral clustering are supported.
Usage
To use the script use python playlist_analyzer.py with any of the following sets of parameters (Optional parameters are in square brackets):
-hor--help- Shows a help message.
-g [-p Playlist_CSV_Filename] [-n Number_Of_Songs_To_Include]- Generates a playlist similar to the given playlist using a neural network.
- An MLP classifier is trained to predict which playlist each track comes from based on its audio features. Then the trained model selects the tracks, from all available playlists, that it deems most likely to be from the given playlist (AKA tracks the user would like, since they are musically similar to their Top 100 list) and creates a Spotify playlist of these tracks.
- Note: The -p argument expects the name of the CSV file containing the audio analysis of the tracks in the playlist, not the playlist ID/URI.
-d [-n Number_Songs_From_Each] [-p Playlist_CSV_Names]- Generates a ‘Dance Party’ playlist from given Playlist CSV file names, picking n ‘danceable’ songs from each source playlist.
- Note: The -p argument expects playlist CSV file names (not playlist ID/URIs) and should be a comma separated list.
-s [-n Number_Songs_From_Each] [-p Playlist_CSV_Names]- Generates a ‘Study Buddies’ playlist from given Playlist CSV file names, picking n ‘study-able’ songs from each source playlist.
- Note: The -p argument expects playlist CSV file names (not playlist ID/URIs) and should be a comma separated list.
-a [-p Playlist_ID] [-n Number_Of_Artists_To_Display]- Shows top occurring n Artists in a Playlist (defaults to showing all artists present in the playlist in order if n is not specified).
-w [-p Playlist_ID]- Writes a CSV file of audio features and metadata for the given playlist.
- Defaults to creating a CSV file for each of the user’s playlist with ‘Top 100’ in the name if no argument is provided.
-c [-a Algorithm] [-n Number_Of_Clusters]- Performs clustering with given algorithm {‘GMM’ or ‘spectral’} and the specified number of clusters.
- Running with no command line arguments will execute unit testing of the various functions.
Note: The following environment variables must be set in order to run the script locally:
SPOTIFY_USERNAME, SPOTIFY_CLIENT_ID, SPOTIFY_CLIENT_SECRET, SPOTIFY_REDIRECT_URI
Sample Output
The following subsections contain example results from the different features contained in this project. Some are links to open a playlist in Spotify, while others are images of plots, or simply text. Note: Any linked Spotify playlists may contain explicit content, parental discretion is advised.
Classification and Prediction
The following two examples show how well the classifier is able to distinguish between musical tastes. It is clear from the original playlists that these two users have very different music tastes. The generated playlists reflect this distinction, and contain a mix of tracks from their original Top 100 list as well as new tracks that they would very likely enjoy (as confirmed with feedback from several users). Note: Removal of duplicates causes some generated playlists to have fewer than N (100 in these examples) tracks.
Example 1: Original Playlist One was used to create Generated Playlist One.
Example 2: Original Playlist Two was used to create Generated Playlist Two.
The classification accuracy was benchmarked with many permutations of parameters, with an example benchmarking output of the MLP classifier is available here. The MLP generally performed better than the Naive Bayes model, correctly labeling ~35% of the dataset. This may seem low, however randomly assigning labels would result in ~8% accuracy, since there are 12 possible playlists to choose from. When you also take into account that some of these 12 users have similar music tastes, a ‘wrong’ classification could still assign the track to someone who would enjoy it, just not the playlist where it was originally found.
Group Playlist Generators
This example Dance Party Playlist consists of 5 tracks from 3 different users’ playlists, and clearly captures the rap/trap essence that is present in each of their playlists.
This Study Buddies Playlist takes 6 tracks from 5 different users’ playlists, creating a relatively cohesive playlist very well suited to quiet group studying.
Overall, these two features depend pretty heavily on how similar the playlists are, since taking the most danceable songs from someone who listens to hip-hop and someone who listens to disco would result in a very strange and non-cohesive playlist. Sequential analysis to minimize the change in audio features between successive tracks could help build cohesion in the generated playlists for these cases in the future.
Top Artists
The output for the top artists feature is more simple (just text) and can be seen below. The following is the output of finding the top 10 artists in the ‘A Top 100’ playlist:
Finding the top artists in A Top 100…
Top 10 artists in playlist:
10 songs - Kendrick Lamar
10 songs - Frank Ocean
9 songs - Kanye West
8 songs - Action Bronson
5 songs - Joey Bada$$
5 songs - BadBadNotGood
5 songs - Anderson .Paak
4 songs - Tyler, The Creator
4 songs - The Weeknd
4 songs - Statik Selektah81 different artists appeared in this playlist.
Click here to see the output of this feature where all the artists in a playlist are displayed, not just the top 10.
Clustering
Clustering was performed using various subsets of the available audio features, and two different clustering algorithms: Gaussian Mixture Model (GMM) and Spectral. The following subsections contain the output for the distribution of clusters among different playlists, a comparison of GMM and Spectral clustering, and a comparison between clustering using all the features versus only using two. Although the data points may not seem to form clusters using two dimensions, when clustered with all available audio features (9 dimensions) they do seem to form unique clusters for different styles of music.
Cluster Distribution Bar Chart
The following plot shows the number of tracks that are assigned to each cluster for each different playlist. The goal of this plot is to emphasize how the different playlists, thus the different users, have different musical tastes, and how that can be identified with clustering. Being familiar with the playlists and the users who provided them, it seems likely that the green line/cluster represents rap/trap music, while the purple line is acoustic/singer-songwriter tracks, and the blue line is for rock/funk. Of course, this is not necessarily the case, but it would make sense based on the content of the different playlists. The other clusters are harder to identify from this graph, however the key takeaway is that clustering is able to differentiate the different music tastes based on audio features.
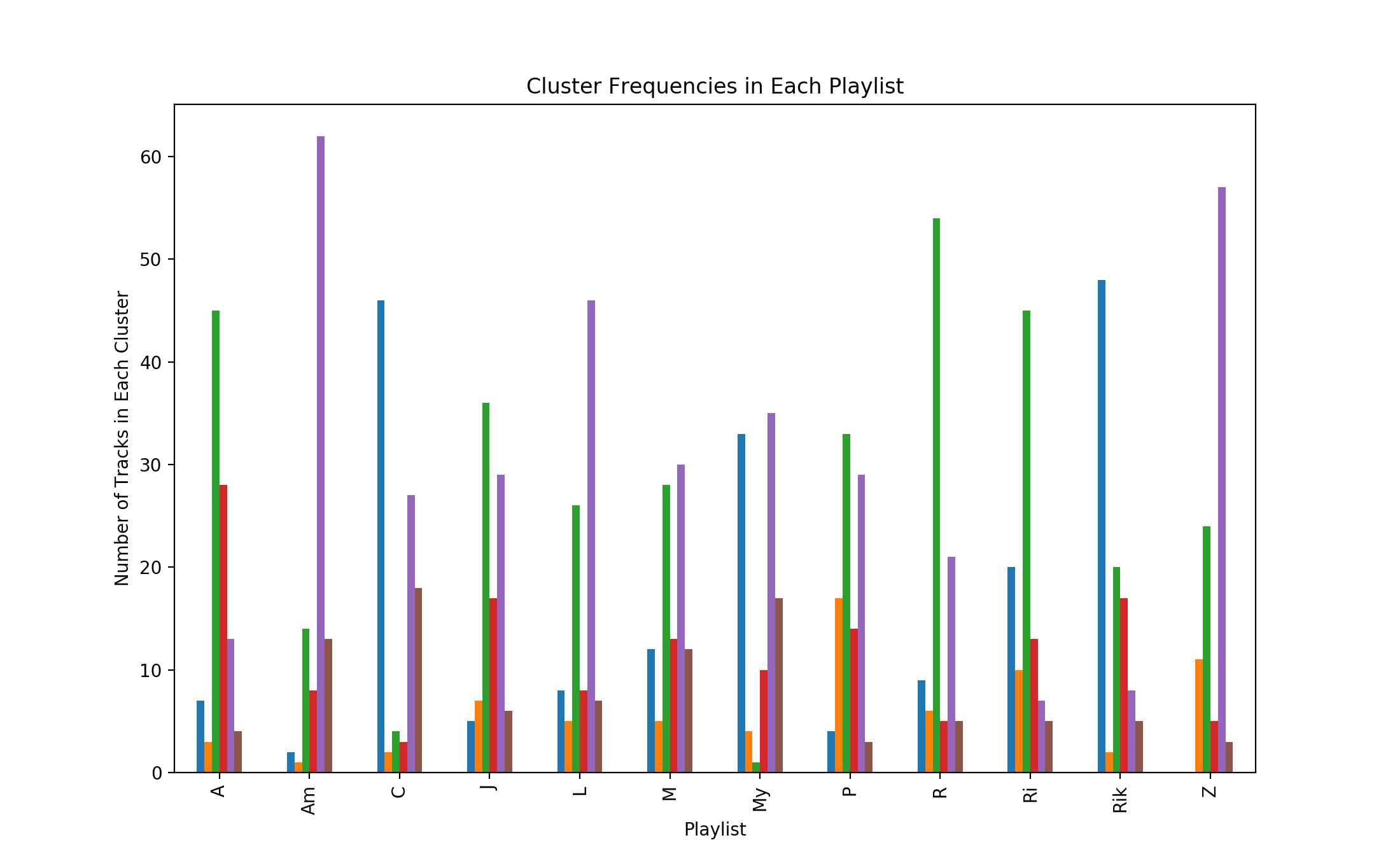 This particular graph uses Gaussian Mixture Model clustering on all the available audio features, using 6 cluster centers.
This particular graph uses Gaussian Mixture Model clustering on all the available audio features, using 6 cluster centers.
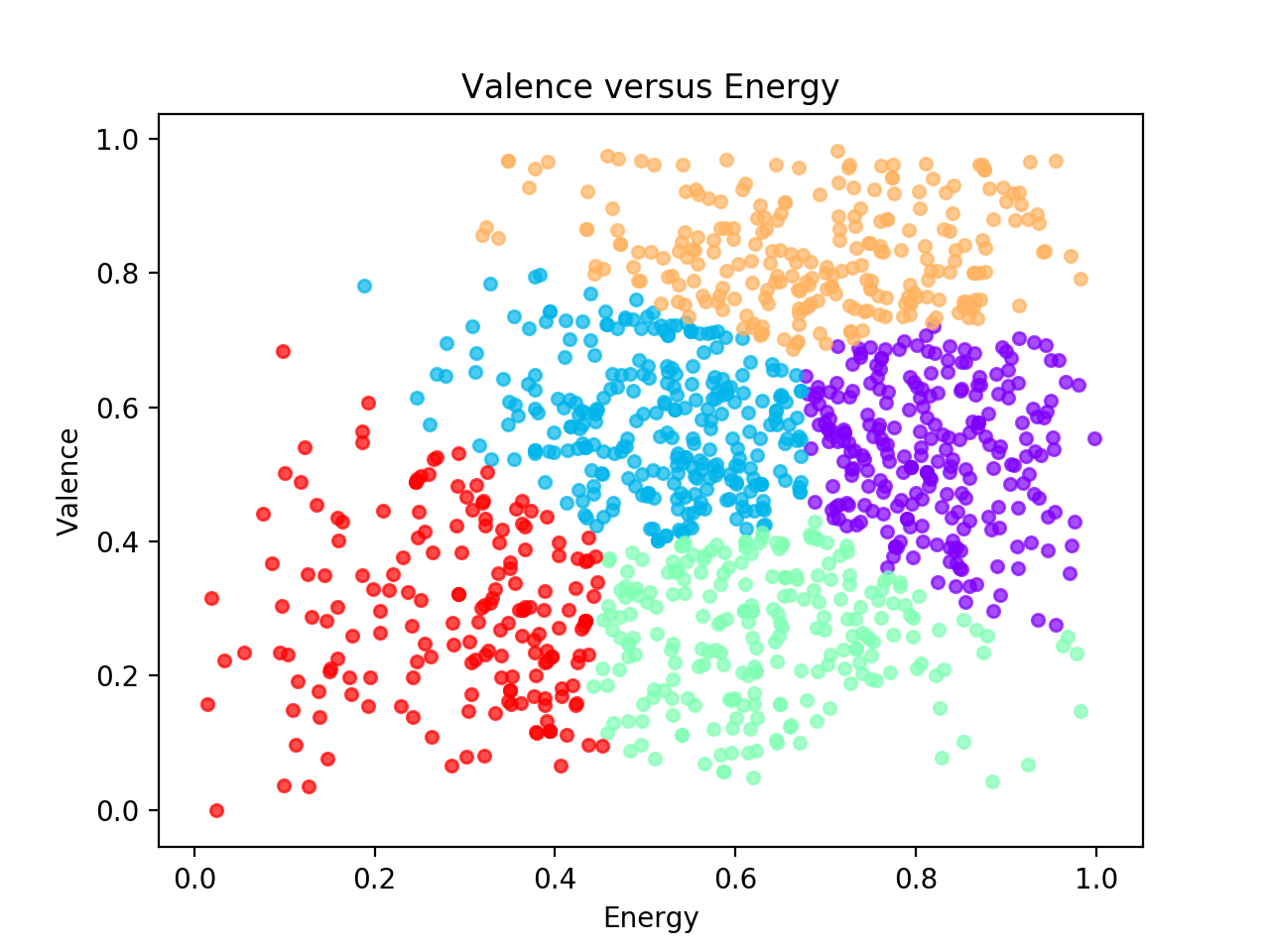
Gaussian Mixture Model versus Spectral Clustering
So far two different methods for clustering have been implemented: Gaussian Mixture Model and Spectral. Below is an example comparing the different clusters found when only the energy and valence audio features are used in clustering. Of course, the order/color of the clusters is arbitrary, however there are several notable differences between the two algorithms in the way the tracks are split up among the resulting clusters. In the future, I plan on adding k-means clustering, and possibly other algorithms as well.
| GMM Clustering | Spectral Clustering |
|---|---|
 |
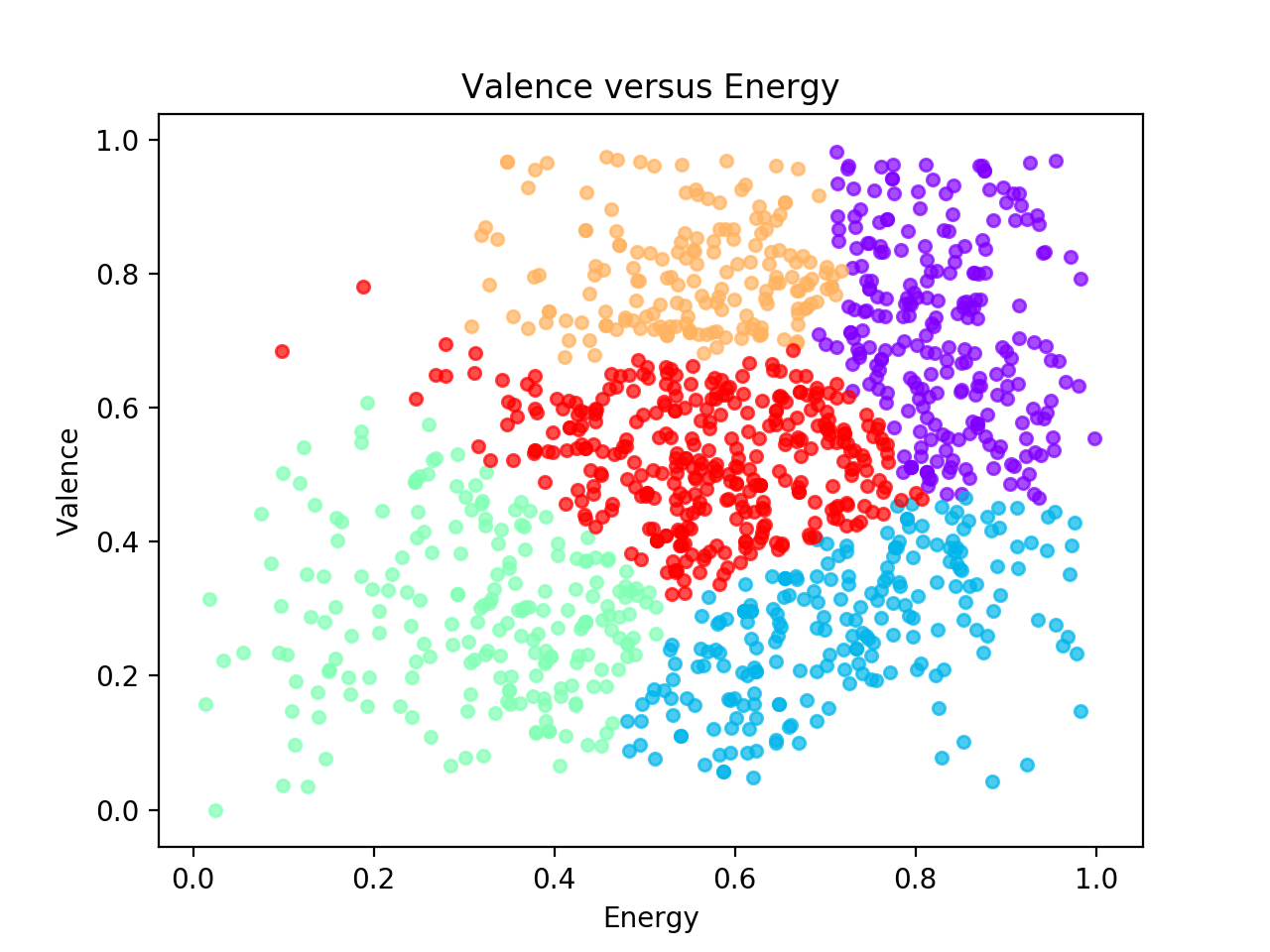 |
Clustering Using All Features versus Only a Subset
The following are both created using spectral clustering with 5 clusters. The left column is clustered using only the valence and acousticness audio features, while the right column used all the available features. Clearly the plots are very different, as the left column shows how we typically visualize clustering, while the right column was clustered using more features than could fit on this 2D plot.
| Using Only Valence and Acousticness | Using All Features |
|---|---|
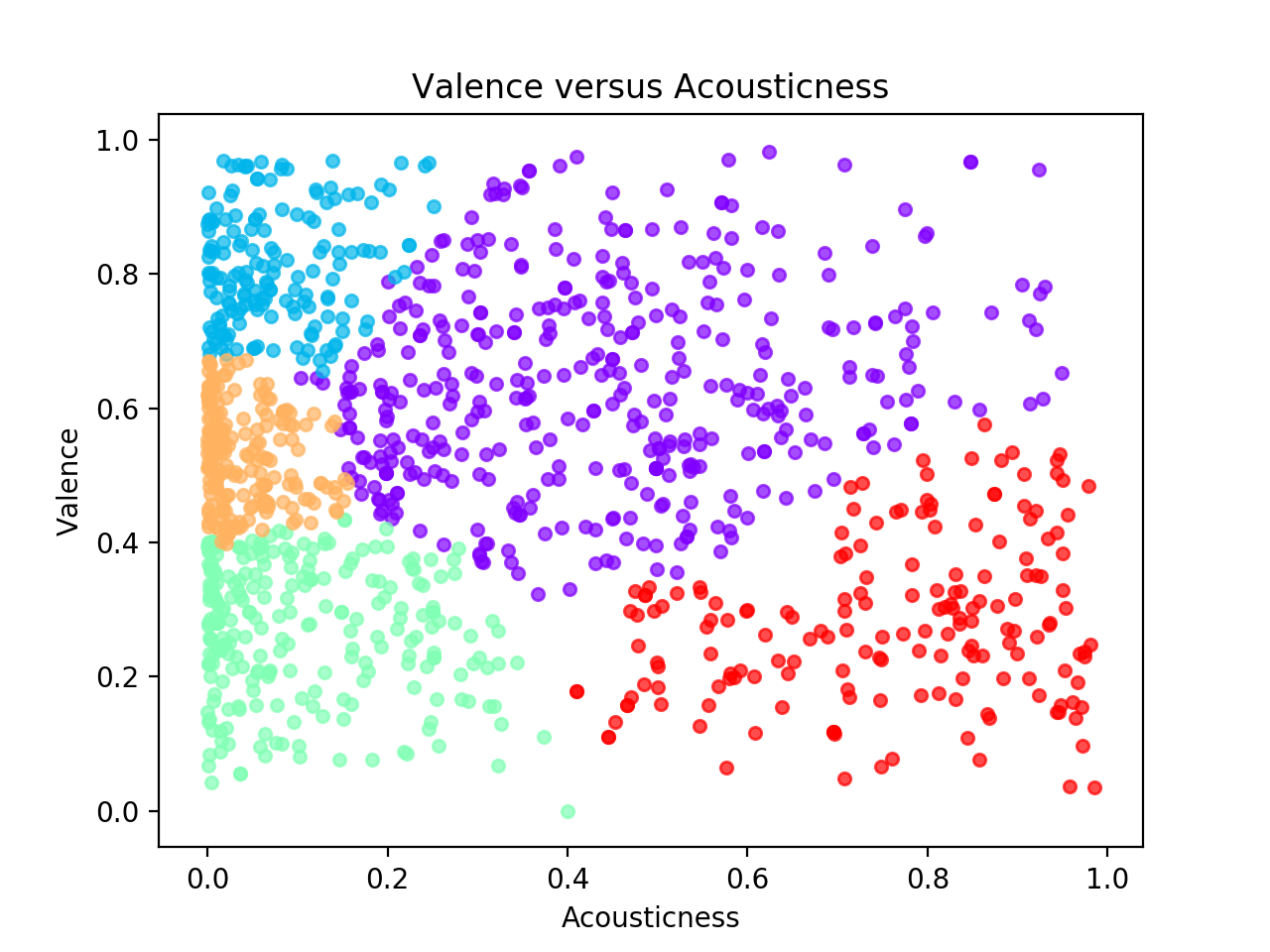 |
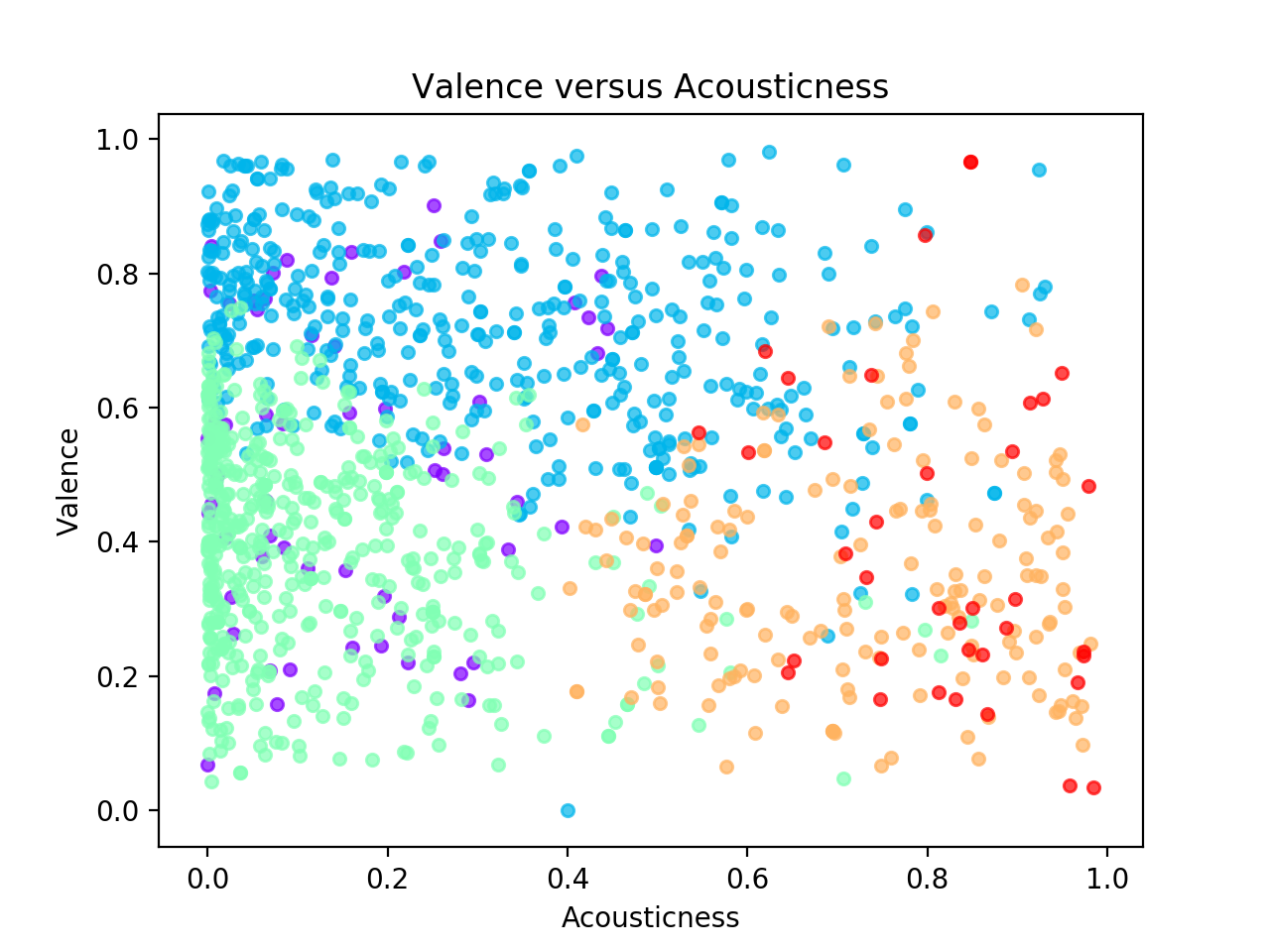 |
Conclusion
This project contains several features to find insights and generate playlists based on users’ Top 100 tracks. Clustering is performed to identify musical trends, top artists are extracted from a playlist, and machine learning is used to generate new playlists based on a user’s Top 100 tracks. Not only can a generated playlist be tailored to a single user, but instead to a group of users in order to create a playlist they would all enjoy. Although currently designed to create playlists for group study sessions or dancing, this framework is easily adaptable to suit other scenarios. This allows a group of friends to instantly generate a collaborative playlist for a given situation, catered to all of their musical tastes. The potential features utilizing this sort of analysis and group-oriented design are endless, and I look forward to continuing to explore the data and the Spotify API as a whole.
Feel free to contact me (mlevin6@u.rochester.edu) with any comments or suggestions about this project!
I have no affiliation with Spotify, I just wanted to explore the API and try to find interesting insights from various users’ Top 100 playlists. All data is provided by the Spotify Web API.